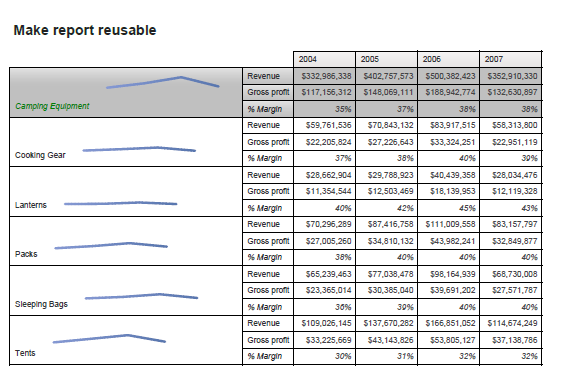
Oracle verions: 2,3,4,5,6,7,8, 8i, 9i, 10g, 10g release2, 11g ( fror linux and MS windows), 12c ( Linux, Solaris and Windows)
'i' and 'g' part of the version name just represents either "Internet" or "Grid"
c for "cloud"
History:
'i' and 'g' part of the version name just represents either "Internet" or "Grid"
c for "cloud"
History:
- 1990: the release of Oracle Applications release 8[59]
- 1992: Oracle version 7 appeared with support for referential integrity, stored procedures and triggers.
- 1997: Oracle Corporation released version 8, which supported object-oriented development and multimedia applications.
- 1999: The release of Oracle8i aimed to provide a database inter-operating better with the Internet (the i in the name stands for "Internet"). The Oracle8i database incorporated a native Java virtual machine (Oracle JVM, also known as "Aurora").[63]
- 2000: Oracle E-Business Suite 11i pioneers integrated enterprise application software[59]
- 2001: Oracle9i went into release with 400 new features, including the ability to read and write XML documents. 9i also provided an option for Oracle RAC, or "Real Application Clusters", a computer-cluster database, as a replacement for the Oracle Parallel Server (OPS) option.
- 2002: the release of Oracle 9i Database Release 2 (9.2.0)[64]
- 2003: Oracle Corporation released Oracle Database 10g, which supported regular expressions. (The g stands for "grid"; emphasizing a marketing thrust of presenting 10g as "grid computing ready".)
- 2005: Oracle Database 10.2.0.1—also known as Oracle Database 10g Release 2 (10gR2)—appeared.
- 2006: Oracle Corporation announces Unbreakable Linux[59] and acquires i-flex
- 2007: Oracle Database 10g release 2 sets a new world record TPC-H 3000 GB benchmark result[65]
- 2007: Oracle Corporation released Oracle Database 11g for Linux and for Microsoft Windows.
- 2013: Oracle Corporation released Oracle Database 12c[66] for Linux, Solaris and Windows. (The c stands for "cloud".)
------------
At the moment the actual version of Oracle database server is 12c (12.1.0.2) that includes the following remarkable features:
- Oracle Database In-Memory
- Oracle Big Data SQL
- Oracle JSON Document Store
- Oracle REST Data Services
- Improvements to Oracle Multitenant
- Advanced Index Compression
- Zone Maps
- Approximate Count Distinct
- Attribute Clustering
- Full Database Caching
- Rapid Home Provisioning
- Oracle Database In-Memory
- Oracle Big Data SQL
- Oracle JSON Document Store
- Oracle REST Data Services
- Improvements to Oracle Multitenant
- Advanced Index Compression
- Zone Maps
- Approximate Count Distinct
- Attribute Clustering
- Full Database Caching
- Rapid Home Provisioning
I’ll also try to place below my first draft of the history of Oracle database innovations and version releases.
2013 – Oracle Database 12c R1
- New Multitenant and Pluggable database concept
- Adaptive Query Optimization
- Online Stats Gathering
- Temporary UNDO
- In Database Archiving
- Invisible Columns
- PGA Aggregate Limit setting
- DDL Logging
- Flash ASM
-
- New Multitenant and Pluggable database concept
- Adaptive Query Optimization
- Online Stats Gathering
- Temporary UNDO
- In Database Archiving
- Invisible Columns
- PGA Aggregate Limit setting
- DDL Logging
- Flash ASM
-
2009 – Oracle 11g2
- SQL Performance Analyzer
- Deferred segment creation
- Smart Flash Cache
- Automatic block repair from Standby DB
- Edition Based Redefinition
- Oracle RAC One Node
- Oracle Restart
- Instance Caging
- ASM Cluster File System (ACFS)
- SQL Performance Analyzer
- Deferred segment creation
- Smart Flash Cache
- Automatic block repair from Standby DB
- Edition Based Redefinition
- Oracle RAC One Node
- Oracle Restart
- Instance Caging
- ASM Cluster File System (ACFS)
2007 – Oracle 11g
- Real-Time SQL Monitoring
- Query Result Cache
- Advanced Compression Option
- SecureFiles LOBs
- Flashback Data Archive
- Data Recovery Advisor
- Automatic Diagnostic Repository (ADR)
-
- Real-Time SQL Monitoring
- Query Result Cache
- Advanced Compression Option
- SecureFiles LOBs
- Flashback Data Archive
- Data Recovery Advisor
- Automatic Diagnostic Repository (ADR)
-
2005 – Oracle 10gR2
- Transparent Data Encryption
- Transportable Tablespace Support
- ASM Command-Line (asmcmd) utility
- OPatch the Patching Tool
- Database Replay
- Active Session History (ASH) Report
- Automatic Segment Advisor
-
- Transparent Data Encryption
- Transportable Tablespace Support
- ASM Command-Line (asmcmd) utility
- OPatch the Patching Tool
- Database Replay
- Active Session History (ASH) Report
- Automatic Segment Advisor
-
2003 – Oracle 10g: first Grid computing database
- Grid computing – an extension of Oracle RAC
- Automated Storage Management (ASM)
- New self-tuning features (AWR, ADDM)
- Recycle bin
- New database job scheduler (DBMS_SCHEDULER)
- Datapump utility
- SYSAUX tablespace
-
- Grid computing – an extension of Oracle RAC
- Automated Storage Management (ASM)
- New self-tuning features (AWR, ADDM)
- Recycle bin
- New database job scheduler (DBMS_SCHEDULER)
- Datapump utility
- SYSAUX tablespace
-
2002 – Oracle 9iR2
- Locally Managed SYSTEM tablespaces
- Data segment compression
- Oracle Streams
- Cluster file system for Windows and Linux
- Logical standby databases with Data Guard
- Default Accounts locked on install
-
- Locally Managed SYSTEM tablespaces
- Data segment compression
- Oracle Streams
- Cluster file system for Windows and Linux
- Logical standby databases with Data Guard
- Default Accounts locked on install
-
2001 – Oracle 9i
- First database to complete the 3 terabyte TPC-H world record
- First database with built-in web services; with integrated data mining; with Hash, Range, Composite and List partitioning; with dynamic memory management; with built-in workflow
- Oracle RAC introduced
- Automated System Managed Undo
- Flashback query
- Oracle Data Guard (new name)
- Dynamic Memory Management
- On-line table and index reorganization
- Resumable backups and statements
-
- First database to complete the 3 terabyte TPC-H world record
- First database with built-in web services; with integrated data mining; with Hash, Range, Composite and List partitioning; with dynamic memory management; with built-in workflow
- Oracle RAC introduced
- Automated System Managed Undo
- Flashback query
- Oracle Data Guard (new name)
- Dynamic Memory Management
- On-line table and index reorganization
- Resumable backups and statements
-
1999 Oracle8i: First internet ready database
- Integrated JavaVM
- Oracle iFS (Internet File System)
- First database with XML support
- First RDBMS ported to Linux
- Statspack utility
- PL/SQL encrypt/decrypt package
- CASE statement in SQL
- User schema concept
- CURSOR_SHARING parameter
- Fast Start recovery
- Log Miner functionality
- OPS Cache Fusion
- Virtual Private Database (VPD)
- Temporary tables
- Drop column on table
- Function based indexes
-
- Integrated JavaVM
- Oracle iFS (Internet File System)
- First database with XML support
- First RDBMS ported to Linux
- Statspack utility
- PL/SQL encrypt/decrypt package
- CASE statement in SQL
- User schema concept
- CURSOR_SHARING parameter
- Fast Start recovery
- Log Miner functionality
- OPS Cache Fusion
- Virtual Private Database (VPD)
- Temporary tables
- Drop column on table
- Function based indexes
-
1998
- First database with Java support
- Breaks the 100,000 TPC-C barrier
- First database with Java support
- Breaks the 100,000 TPC-C barrier
1997 Oracle8: First Web-enabled database
- Object types
- SQL3 standard
- Parallel DML statements
- Index Organized tables (IOTs)
- Reverse Key indexes
- ROWID format
- Advanced Queuing
- Recovery manager (RMAN)
- Object types
- SQL3 standard
- Parallel DML statements
- Index Organized tables (IOTs)
- Reverse Key indexes
- ROWID format
- Advanced Queuing
- Recovery manager (RMAN)
1996 – Oracle 7.3
- Standby Database
- Bitmapped Indexes
- Partitioned Views
- Index rebuilds
- db_verify utility
- Spatial and Context Data Options
- Histograms
- Oracle trace
-
- Standby Database
- Bitmapped Indexes
- Partitioned Views
- Index rebuilds
- db_verify utility
- Spatial and Context Data Options
- Histograms
- Oracle trace
-
1995 – First 64-bit RDBMS
1992 – Version 7
- First a full applications implementation methodology (AIM)
- Partitioning introduced
- Stored procedures and triggers
- Referential integrity with Foreign Keys
-
- First a full applications implementation methodology (AIM)
- Partitioning introduced
- Stored procedures and triggers
- Referential integrity with Foreign Keys
-
1988 – Version 6
- First row – level locking
- First to introduce PL/SQL
- On-line database backups
- B*Tree indexes implemented
- Concept of tablespaces introduced
- Rollback Segments introduced
- First row – level locking
- First to introduce PL/SQL
- On-line database backups
- B*Tree indexes implemented
- Concept of tablespaces introduced
- Rollback Segments introduced
1987 – First SMP database
1985 – Version 5
- First parallel server database
- First client-server database
- First distributed queries
- First parallel server database
- First client-server database
- First distributed queries
1984 – Version 4: First database with read consistency
Read consistency concept enabled readers and writers to access the same data without one blocking the other.
Read consistency concept enabled readers and writers to access the same data without one blocking the other.
1983 – Version 3: First portable Oracle Database
- First portable database offered a choice of what hardware and operating system platform to run on
- First database written entirely in C
- First VAX-mode database
- First portable database offered a choice of what hardware and operating system platform to run on
- First database written entirely in C
- First VAX-mode database
1979 – Version 2: first Oracle Database
First RDBMS version released in 1979 was called Oracle V2. Why not V1? There were two reasons for that: a concern that a version 1 would not awake potential customers’ interest and to show a pseudo- leadership compared to the competitors. First version of RDBMS was created with assembler.
First RDBMS version released in 1979 was called Oracle V2. Why not V1? There were two reasons for that: a concern that a version 1 would not awake potential customers’ interest and to show a pseudo- leadership compared to the competitors. First version of RDBMS was created with assembler.
So that was the Roadmap of Oracle Database version releases, current status and the brief history. In case of minor mistakes please correct in comments and I’ll update it. Thanks